給自己一個(gè) 高薪 高逼格 的未來(lái) - IT人才
(以下數(shù)據(jù)來(lái)自Jobshow)
0基礎(chǔ)學(xué)習(xí)? 初中高學(xué)歷?
課程分級(jí)教學(xué),總有適合你的課程
我是0基礎(chǔ)
4-6個(gè)月成為IT工程師
初、高中畢業(yè)生
量身定制課程體系
本、專科畢業(yè)生
實(shí)訓(xùn)5個(gè)月
具備2年工作經(jīng)驗(yàn)

「互聯(lián)網(wǎng)+IT人才」的T型人才
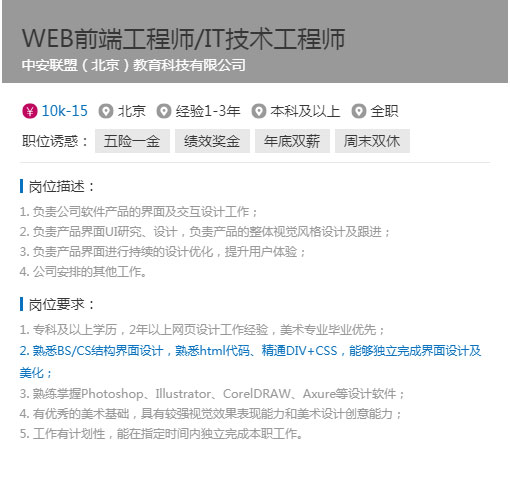
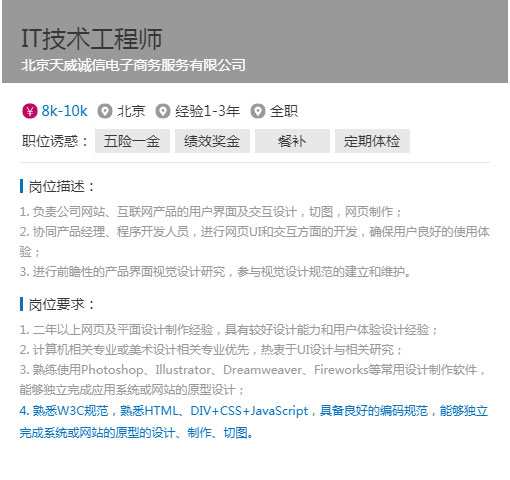

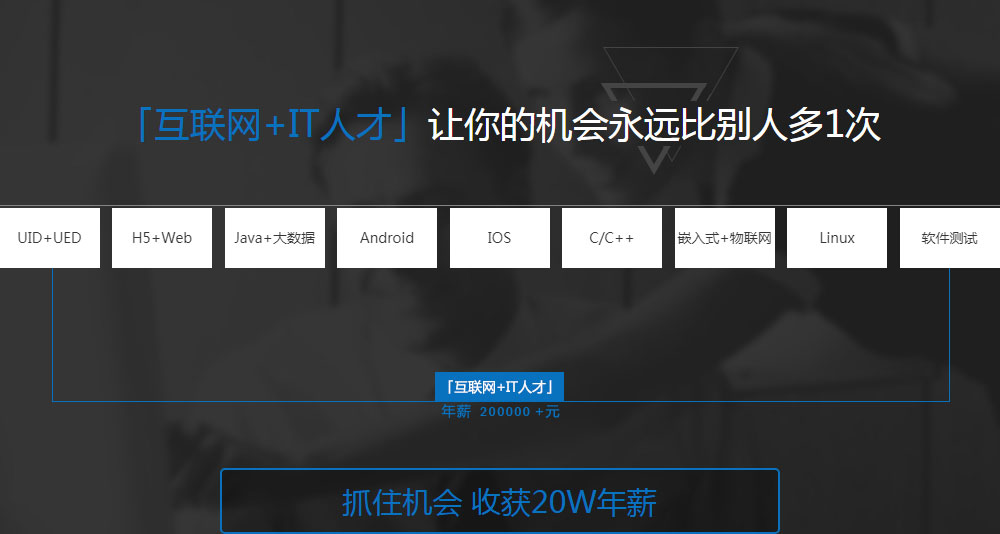
以就業(yè)為導(dǎo)向,從企業(yè)實(shí)際需求出發(fā)
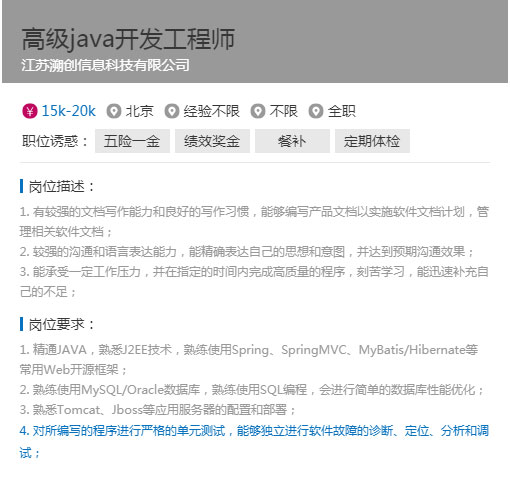
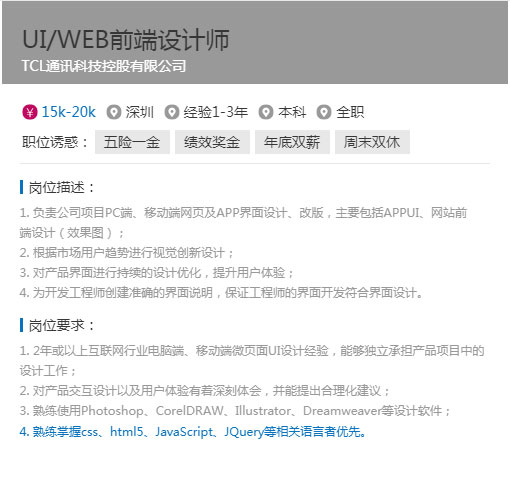
市場(chǎng)需求巨大的崗位



















超過(guò)20000人獲得了鍍金池職業(yè)規(guī)劃方案

學(xué)員關(guān)心的問(wèn)題
你是否有,這樣的困惑?
1、自己適合學(xué)嗎?
2、學(xué)不會(huì)怎么辦?
3、學(xué)完能進(jìn)哪些企業(yè)?
4、學(xué)完能掙多少錢(qián)?
5、學(xué)費(fèi)多少錢(qián)?
6、不知道學(xué)什么課程?






我們?yōu)槟?精挑細(xì)選「互聯(lián)網(wǎng)+IT人才」課程體系

眾多名校 保駕護(hù)航
眾多學(xué)員在這里重新開(kāi)啟人生 我要改變











國(guó)內(nèi)IT企業(yè)任你選 進(jìn)入500強(qiáng)
這些企業(yè)里面都有你的學(xué)長(zhǎng) 我要加入
中國(guó)聯(lián)通
華為
惠普
IBM
富士通
亞馬遜
用友
淘寶網(wǎng)
新浪
亞信聯(lián)創(chuàng)
電訊盈科
百度
騰訊
阿里巴巴
58同城
迅雷
微軟
搜狐
甲骨文
東軟
軟通動(dòng)力
四達(dá)時(shí)代
你的明天會(huì)比他們更美好